
Hey folks, welcome to the digest! This week, I had the pleasure of catching up with Can, CTO of Felt, about building collaborative, browser-based software in GIS world, where desktop software has dominated.
Thanks to reader Ankesh for suggesting the interview.
My highlights
- Felt’s multiplayer backend is powered by a single scaled-up server.
- After the initial page load, there are no fetch requests – all communication with the server goes over WebSocket.
- When computationally-intensive work (like tiling) is needed, pipelines that run on AWS Lambda are triggered.
- SVG was too high-level; WebGL is too low-level; HTML Canvas API is the Goldilocks pick.
Origin story
Paul: What’s Felt’s origin story?
Can: Around late 2020 my co-founder Sam [Hashemi] had just left Remix and was thinking about what to do. I had been at Uber. We had known each other for a long time, and started talking about working on something related to climate change.
We were both in the Bay Area. I think around that time the orange skies happened and also COVID. So we were constantly looking at maps: weather quality data, COVID maps, etc.
And we wondered, “why do these maps suck so much?” There's kind of this clunkiness to maps compared to Google Docs or Figma.
We were like, “it's not that hard to do this kind of stuff”. It turns out it's not that easy either – but it's not an insurmountable problem.
So we thought, why don't we just work on making maps easier and see where it goes.
Paul: How do you describe the product you wound up building? What’s the pitch?
Can: The short pitch is: the best way to make maps on the internet.
The ‘internet’ part is key, because if you look at how the industry works, it's dominated by desktop software. ArcGIS, ArcGIS Pro, QGIS, etc. And that's where the world ends.
What if you didn't start or end there? What if you just did the entire thing on the web?
The ‘best’ part is that we wanted to make the tool more about what people are trying to do versus all the technical things that we can do. We thought “what if you build the tool with the goals in mind, versus technical capabilities in mind”.
Paul: What’s a fun example of someone using Felt?
Can: People make a lot of maps for event planning. The Grateful Dead created Felt maps with locations along their tour.
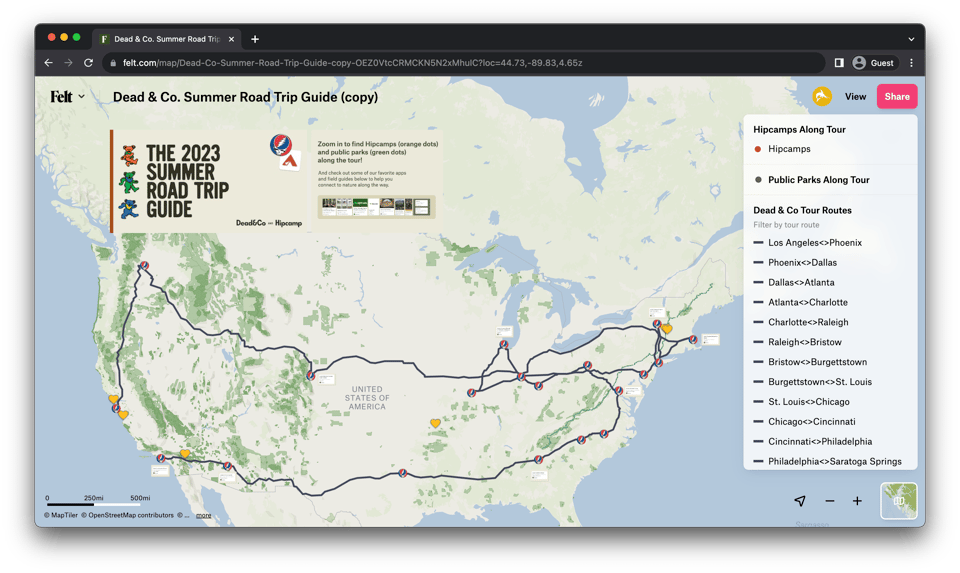
Client-side tech
Paul: Let's get into the tech. What's the stack on the client side?
Can: This client stack is a MapLibre renderer, and our own annotation layer written in [HTML] canvas. And we have the annotation tools, mostly written in React.
The data comes tiled from the server in a way that like our client stack knows how to render, and it's optimized for web. A lot of the magic there is that the data is specially formed so that it renders quickly and is appropriate for the map you're looking at.
Paul: In terms of sort of appropriate density at different scales?
Can: Yeah. One thing that's tricky is, let's say you have a 500 gigabyte data set. People have this expectation that I should be able to see this data in its entirety. If you do the math, it's like, are there enough even pixels to see all the data?
It turns out that at every zoom level, you're looking at a different map. Online maps do this very smoothly. If you only see cities, and you zoom in, city labels disappear.
Google and Apple do this for street data. We want to do the other side of data. We have a tiling engine based on Tippecanoe. It renders a different layer for each zoom level you're looking at.
So at every zoom level, it shows you as much as possible, while also making sure that it is reasonable for the browser to render. That is an art as much as a science, because different people have different expectations.
Backend architecture
Paul: And the back end, I understand that’s in Elixir? How did you kind of end up at that decision?
Can: There's sort of two back ends of Felt.
The client – that’s the MapLibre, the React annotation, the canvas rendering – talks to an Elixir backend.
And then there's the pipeline, which is written primarily in Python. It’s a lot of Python CDK scripts to manage Tippecanoe and GDAL.
Why did we pick Elixir? Honestly, the biggest reason was WebSockets.
We wanted to have Felt be collaborative from day one. With Elixir, we built it, and it just works. The abstractions were super easy for me to wrap my head around. It has a very tiny abstraction over WebSockets called channels.
I don’t think we have any Ajax in the app. Everything happens through WebSockets. Elixir just makes that stuff so trivial to write.
Paul: If I understand correctly, an advantage of Elixir here is you can kind of have multiple servers and connections can come into any of them and they kind of just do the right thing?
Can: That part is an advantage. We don't currently use it. Well, that's not exactly true, actually, we do use it, but it's implicit. We deploy 10+ times a day. When we do a deploy, Render spins up another instance and then they cluster automatically with libcluster.
So we use it during deploys, but otherwise, I don't think our CPU has ever hit more than like two or three percent [utilization].
For memory, we're aggressively over-provisioned, because it's cheap. The reason why we picked Elixir was that the developer experience is much simpler than having Rails and Action Cable and Node or Redis or something like that.
We just have a single app that every Felt developer can install. The developer experience was the key.
State synchronization
Paul: So when it comes to state, you've got the WebSocket connections. I take it you've implemented a state synchronization layer on top?
Can: Yeah. Right now the way we do collaboration is that we loosely follow a Figma model, where the last write the server sees wins. And build our data structure as much as possible so that merge conflicts are not very common, which works surprisingly well.
The key insight there is, a lot of the value of real-time collaboration is helping people understand that there's a single version in the cloud, versus multiple people actually editing the document at the same time. People want to see other people's cursors, but it's extremely rare that I want to drag this North and you want to drag it South.
We're not using something like Yjs, we're not using any of the CRDT or OT structures. We're just structuring the data as deeply as possible, so that merge conflicts don't happen often.
Paul: Do you end up sparsely loading the document data? You mentioned that the map data and base layers are tiled. Is that also true of the user-editable data?
Can: We have what we call “elements” and “layers”. Elements are essentially what users put in. Layers are a representation of data that have been tiled by the pipeline.
When you load a map, we load all the elements directly. They're actually written into the HTML from the server. So they're not sparsely loaded.
HTML rendering has never been the bottleneck. The bottleneck has been getting that data from the database.
Geodata retrieval and processing
Paul: For the database, are you using Postgres with PostGIS?
Can: We do have PostGIS enabled. But surprisingly, we only have a single query in the entire app that uses PostGIS, and that's the extent query where we get the bounding box of all the elements.
We store the elements as a GeoJSON blob. So we use ST_Extent to get the bounding box of these elements. And that's it. So it has not been sort of like a big thing for us, to be honest.
PostGIS is super powerful, but we don't want to use it in the hot paths. I can make queries that are wildly powerful, but like they're not the fastest. We do a lot of geo stuff out-of-band in the pipeline instead.
Paul: Are pipelines invoked in real time for users? Does a user do some action on the client that fires off a pipeline?
Can: We went all-in on the serverless methodology, and it's been wildly successful.
When you drag and drop a file, Elixir gets a pre-signed upload URL from S3 and then passes it over to the client. And it creates a job ID and then says to the pipeline, “Hey, I created this job ID and I'm going to start watching this S3 location now”.
And the pipeline starts processing it, and then drops the files to where the Elixir app is watching. Once the Elixir app sees the files, it tells the JavaScript to request tiles, and we load.
One of the key decisions we made is that from the pipeline's point of view, there is no Elixir app. There is no JavaScript. It is entirely decoupled.
All it does is, “oh, there's a file, and it says I should drop files into this other bucket.” That's it.
Paul: And these are essentially [AWS] Lambda functions?
Can: Yeah, they're essentially Lambda functions.
We try to use as much Lambda as possible. We still have a couple ECS escape hatches when we hit Lambda limits.
Transitioning to Canvas
Paul: Jumping back to the client side, Tom Hicks wrote a pair of blog posts about Felt’s transition from SVG to Canvas. What limits did you hit with SVG, and how did they manifest?
Can: The limit we ran into is that all the DOM calls add up really fast.
As a work-around, when you interact with the map, we tried to batch these operations. That would cause two issues. One is that it would stop the world all of a sudden at the end of a zoom. You're like using the map, it's fluid, then you have to zoom and things will be janky for a second.
The other problem is that we would essentially just scale things as you're zooming in and out until we rerendered them. You would have these ugly artifacts, because you have this shape, you zoom in, and all of a sudden it becomes super pixelated.
Paul: Did you evaluate Canvas against WebGL, or was it always obvious that you wanted to go with Canvas?
Can: Canvas is slightly higher level than GL. WebGL would probably give us the most control if we were to write shaders for everything. But we wanted to let browsers do some of the work.
I don't want to build text layout from scratch again. And I don't want to build event handling from scratch again. With canvas you have to build from, like, 70%. That's better than 20%.
Paul: And so, I guess, you haven't really hit performance limits on Canvas?
Can: That's not exactly true, but the things that we had to do to make Canvas fast have been manageable. For example, we did run into limits around text on canvas. So we had to cache the text into rasters.
We also render simplified versions of certain things like long routes. Let's say you have a route all the way from San Francisco to New York. It's millions of vertexes. We simplify them. You can think about it as, we Tippecanoe them on the client.
Paul: So the idea there would be, like, the client would have the whole vertex path of the route in memory, it simplifies it, and then sends it to the canvas API?
Can: Exactly, yeah.
Paul: That’s all my questions, is there anything else you’d like readers to know?
Can: First of all, thanks for the time. We love your blog posts, like the Figma investigation that came up so many times in our own discussions.
Our team enjoys going deep on frontend tech. We are hiring for FE folks who enjoy pushing the limits on this stuff, and encourage folks to say “hi” at felt.com/careers.
Until next time,
-- Paul
You just read issue #28 of Browsertech Digest. You can also browse the full archives of this newsletter.