
Hey folks, welcome to the digest! Today’s issue is about a pain point developers encounter when shipping desktop-class apps to the browser.
File editors and database apps
Most desktop applications are what I call file editors.
By file editor, I mean that the user selects a file on disk, and the program loads it into memory. User changes are applied in-memory and periodically saved back to disk.
Most web apps, by contrast, are what I call database apps.
Instead of loading a whole file into memory upfront, database apps render views of the data by fetching data from a database as needed to render the UI. When the user makes changes to the data, those changes are persisted back to the database via API calls.
Database apps are a good fit for “CRUD” tools like calendars, todo lists, and tools with three-letter acronyms containing “manager” (CMS, CRM, PIM).
One of the challenges of writing desktop-class software that runs in the browser is that file editors do not translate as naturally to the architecture of the web as database apps do.
To understand why these apps work differently, let's look at one.
Figma is a file editor
The design tool Figma is a good example of a file editor that runs in the browser.
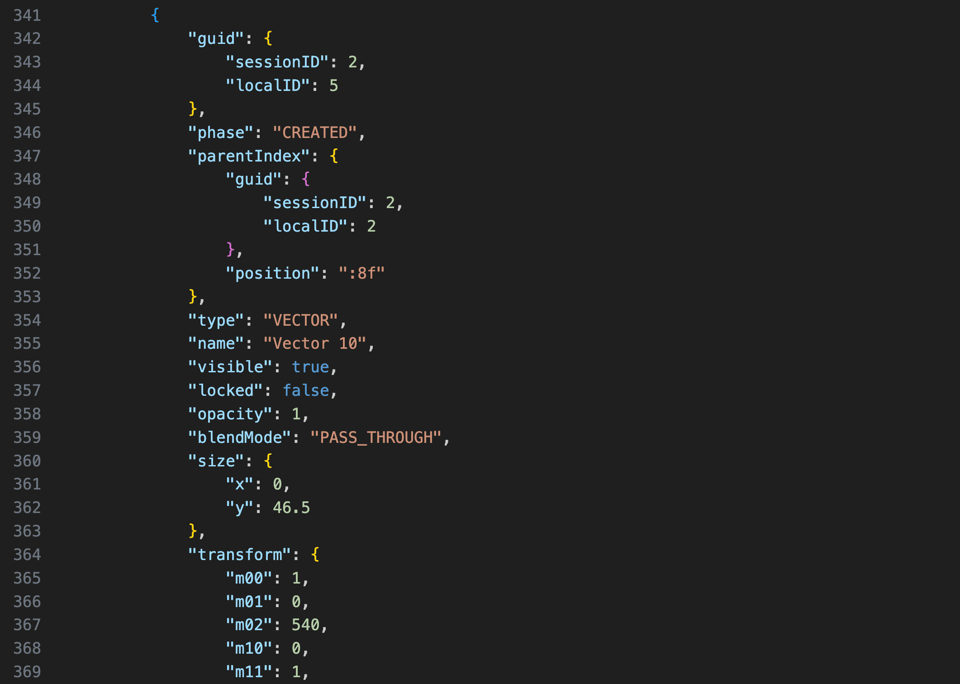
When you open a Figma design, your browser downloads (over WebSocket) a “Fig file” corresponding to that design. The file contains binary data serialized with kiwi. Kiwi is a binary format similar to Google’s Protobuf, open-sourced by former Figma CTO Evan Wallace.
You can think of a kiwi file essentially as compressed JSON. Officially, the kiwi schema used by Figma is undocumented, but there have been some attempts to reverse-engineer it, and at least one third-party tool supports it.
Translated to JSON by a third-party tool, it looks something like this:
S3 as a filesystem
Figma persists these Fig files to Amazon S3.
A naive approach would have been for the client to treat S3 like a network file system and use it the same way a desktop app would use its local file system. This would have two problems:
- The whole file would have to be sent for every change, which is a waste of bandwidth as files get large.
- Figma supports multiple concurrent users per document. If every change caused the entire document to be rewritten, race conditions from concurrent edits would cause data loss.
Figma avoids both of these problems by taking a more sophisticated approach. When you open a Fig file, it’s actually loaded in two places: in your browser, and on a server.
Instead of writing back the entire file on each change, clients stream back only the changed data. The server applies those changes to its own in-memory copy to keep it synchronized.
The tricky part is that when multiple users open the same Fig file concurrently, Figma’s infrastructure needs to ensure that they are all connected to the same server. That server can then be the sole authority on the state of that document, and write to it without race conditions.
Why not use a database?
Figma stores file metadata in a Postgres database. Instead of going to the trouble of using S3 too, they could have also used the database for document data, in one of two ways:
- They could stuff the whole document into a binary blob or json(b) column next to the metadata.
- They could represent the document itself as rows and tables in a relational database.
#1 is essentially (ab)using the database as a file system, which is bad.
#2 at least has the aura of using the database as a database, but it adds a bunch of complexity to the application layer, which needs to be able to translate between a document representation in memory and a relational representation in the database.
In either case, another consideration at scale is that S3 can be 10-100x cheaper byte-for-byte than a database. The query capabilities available in a database come at the cost of computational overhead, and it’s a waste to pay that overhead when you have a known, file-like access pattern.
Durability
Writing the whole document to S3 is relatively slow, so Figma only does it every 30-60 seconds. But if the system responsible for writing those checkpoints fails (say, the power goes out), Figma doesn’t want to lose 30-60 seconds worth of changes. So they buffer changes at a higher frequency by saving them to DynamoDB, as a write-ahead log.
Generalizing Figma’s approach
This post came out of research we’ve been doing towards building an open-source document database that takes a similar approach.
Recently, we introduced “locking” into Jamsocket and Plane, which can guarantee that at most one backend runs per document, motivated by desire for a Figma-like data architecture.
If these problems resonate with problems you’ve experienced building browser-based apps, please drop me a line by replying to this email, I’d love to learn more about the problems you’ve encountered.
Until next time,
Paul
You just read issue #24 of Browsertech Digest. You can also browse the full archives of this newsletter.