
One of the Chrome updates at Google I/O this year was that Chrome 126 ships with Gemini Nano, a version of Google's Gemini model scaled down for edge devices like phones and browsers.
There are two versions of Nano, with 1.8B and 3.25B parameters respectively. By contrast, GPT-4 is rumored to have 1.7 trillion paramters.
I am not sure whether the version that ships in Chrome is the 1.8B or 3.25B version. The model is not currently open-source, although I did come across an unofficial dump of the weights extracted from the Chrome binary while writing this.
First impressions
A tweet went viral yesterday showing a demo that prompts Gemini in real time as the user types.
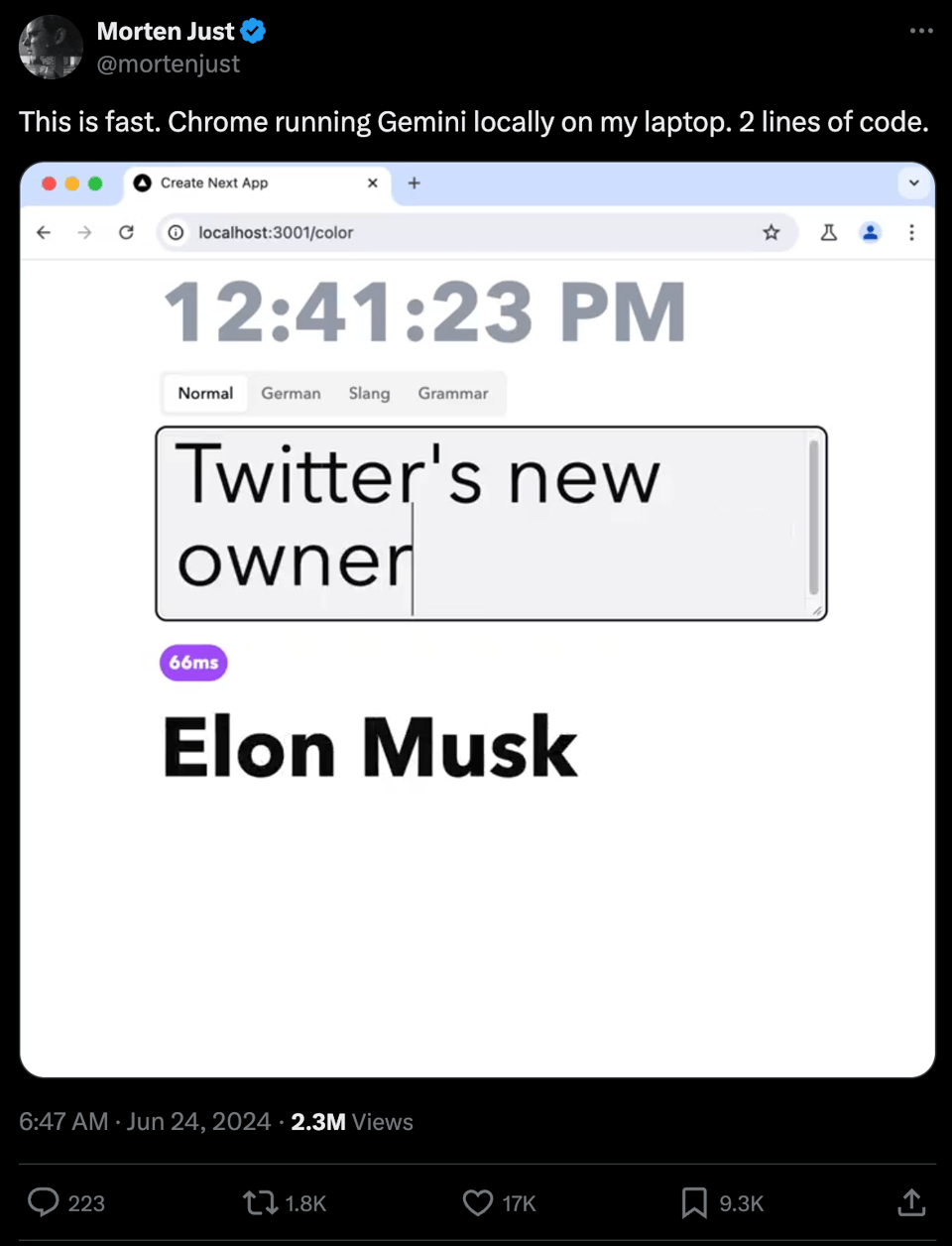
The first thing that stands out is that it's very fast. The demo includes a measure of the latency, and responses often come back in double-digit milliseconds.
I've often said that network latency doesn't really matter in LLM inference because most of the latency is in the compute itself -- the effort it would take to eliminate a 50ms round trip doesn't really move the needle when the full response streams back over a matter of seconds. But for the type of high-frequency, low-latency responses in this demo, performing the inference on-device makes a world of difference.
Experimenting with Gemini
Google has an early preview program for Gemini, but you have to have an idea in mind to apply. I just wanted to get a feel for its capabilities. Fortunately, Lightning Joyce on Twitter found a way to access it in Chrome Canary.
The API is incredibly simple. You create a session with window.ai.createTextSession, optionally passing temperature and topK parameters. It returns a promise to await.
Then, you call session.prompt with a text prompt. It also returns a promise to await, which will contain the model's response. A streaming API is also provided, presumably for ChatGPT-like token-at-a-time streaming although I didn't try it.
Results are hit-or-miss. With the temperature set to 0, it's pretty decent at generating valid JavaScript for simple tasks:
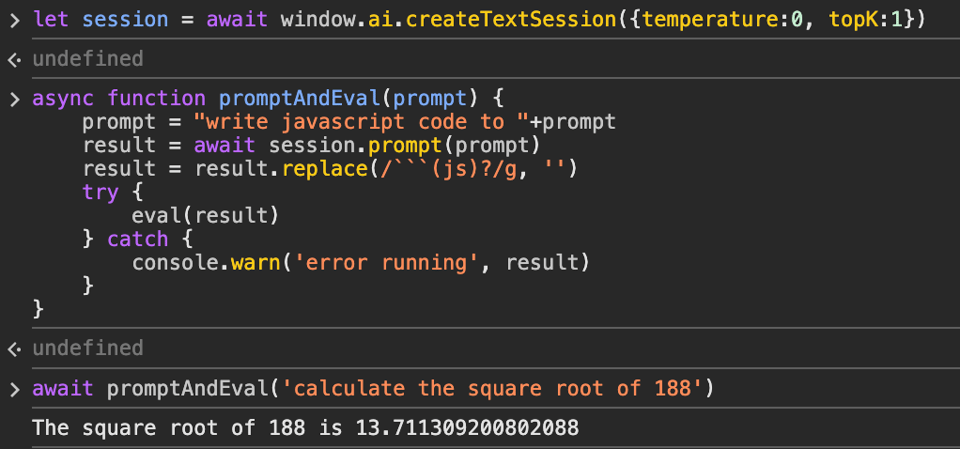
(It tends to insist on returning markdown; even when asked for code, it likes to return a markdown code block.)
I also had success getting it to return structured data as JSON.
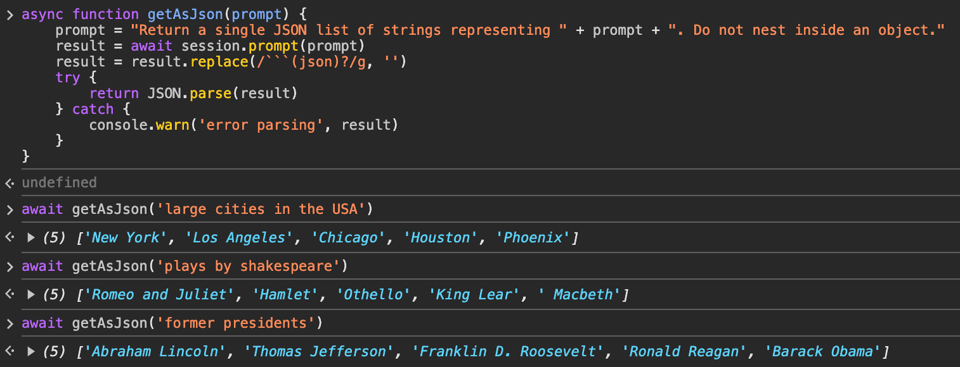
The examples in this post are admittedly a bit cherry-picked. I did encounter a few complete hallucinations, and more commonly encountered responses with unparseable syntax, usually because they terminated without completion.

I also found inference on my M3 MacBook Pro to be 2-4x slower than in the demo, so the truly low-latency examples in the demo that went viral will be out of reach to people on most hardware for some time.
The future
Google warns that this is an experiment, and the API is likely to change.
I believe that Google is coming from a good place with this experiment. They know that developers will be tempted to use WebGPU and Wasm to ship client-side models in their apps. If the browser itself has a built-in LLM anyway, there's a certain technical logic to exposing that LLM to apps.
That said, there are certain political implications of this. If this experiment leads to a standard web API for AI but Gemini Nano isn't open sourced, each browser will have a differently-behaving AI API, and tuning apps for each browser's AI will become a non-deterministic version of the browser compatibility hell that developers faced in the IE era.
Even if Google does release the Nano weights (which I suspect is likely if they decide to expose these APIs in Chrome stable), that would be seen as political because it means they control the web-standard LLM.
In a way, there's parallels here to WebSQL, which ultimately did not become a standard because it was tied to one implementation (sqlite), even though that implementation was open source.
In the case of WebSQL, WebAssembly provides a path for applications to ship sqlite rather than using the browser's built-in version. While this is technically possible with an LLM as well, the costs of every app shipping 1GB+ of model weights are a lot higher (on both the client and server) than each app shipping a few MB of sqlite bytecode.
Until next time,
-- Paul
PS. we are hosting an NYC Browsertech happy hour tomorrow. It's now officially full, but if you read this far and are on the waitlist, reply to this email I'll see what I can do ;)
You just read issue #38 of Browsertech Digest. You can also browse the full archives of this newsletter.