
This week on the Browsertech Podcast, I talked to Breck Fresen and Billy Littlefield of Row Zero about Row Zero, a browser-based spreadsheet that is built to be responsive even at billions of rows.
To do this, they give each spreadsheet its own EC2 instance, which loads the entire sheet into memory. This is reminiscent of a session backend, and is a big contrast to what other browser-based spreadsheets like Google Sheets do, which is to run the spreadsheet engine on the client:
Breck: Many people think of [Google Sheets] as a hosted product, but all the compute is actually happening in JavaScript on your laptop. That's one of the reasons that it's so slow, and even slower than desktop Excel.
Most serious spreadsheet users use desktop Excel, like all the New York i-bankers, none of them are using Google Sheets. And a big reason is performance.
With Row Zero, we don't run client side, we run in the cloud. So when you create a new workbook, we're spinning up compute in AWS behind the scenes. And we can scale that thing up as big as your model or your data set needs to be, and so that that's really where the performance is that, (1) we're not running in JavaScript. It's written in Rust, it’s not happening in JavaScript in the browser. And (2), we’re not constrained to the CPU and memory resources of your laptop. It's running on an arbitrarily large server on the cloud.
To make it responsive, they move the compute closer to where the user is:
Breck: When you use Excel or any local application, it's very responsive.
When you hit a key, type in a formula and hit enter, you get an instant answer. The spreadsheet user interface sets that expectation that you're going to have this instant experience. But if we're putting that compute in the cloud, every time you're typing in Row Zero and then hitting enter, that's a round trip to the cloud and back.
Isn't that going to feel slow? What we do to get around that is we spin up the compute or connect you to compute in the closest AWS region. AWS is now in 30 different regions worldwide, not even counting their local zones. If you count AWS local zones, which is like kind of like a baby AWS data center, they've got something like 60 more of those.
These days, you're really never more than a couple of hundred miles from an AWS data center. And the speed of light is pretty fast. So we can go to the server and back and have it feel just like a native desktop application, but with way more compute and network connectivity behind it.
In other words, rather than running the entire application, the browser becomes a thin client to an application that runs on the server.
Architecturally, this reminds me a lot of pixel streaming approaches, which I have written and talked on the podcast about in the past. The difference is that rather than rendering pixels on the server and sending a compressed video stream to the client, they just send a compressed representation (as gzipped JSON) of the data needed to render the current view.
I think of this as a third option along a spectrum between a "local first" architecture (where the client manipulates a local copy of the document that is synchronized with the server) and pixel streaming.
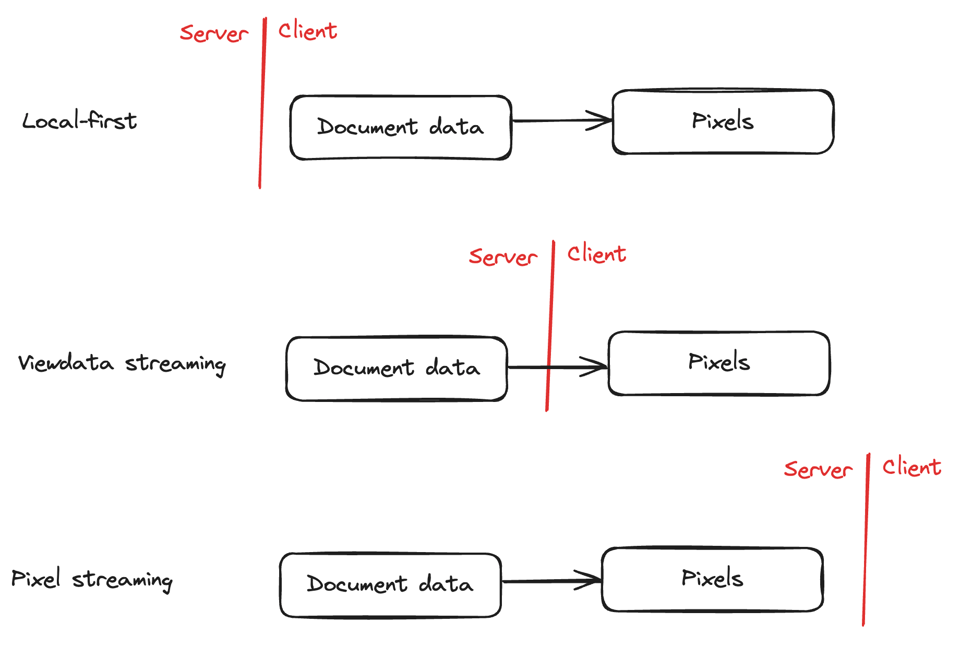
As with pixel streaming, the nice thing about streaming viewport data is that regardless of how large the underlying dataset is, the amount of data that can appear on screen is capped at some low constant.
Breck: We know your where your viewport is, which cells in the spreadsheet are visible. And then we only have to send down the data that you're looking at.
Even though there might be multiple gigabytes on the server, you're only looking at maybe a few kilobytes at a time.
Like pixel streaming and other thin-client models, the obvious downside to this approach is that it doesn't work offline. This is a reasonable trade-off for data/compute-intensive applications that exceed the capabilities of the client anyway.
This architecture also simplifies multiplayer, because they naturally have an authoritative server to use:
Paul: If multiple people are sort of have the same sheet open at a time, then are they talking to the same EC2 instance?
Breck: They are. Yeah. That's another really nice benefit of just doing everything in the server, is it really simplifies multiplayer.
[OT and CRDTs are] very complicated software to get right. For us, it is much simpler, because we just have a transaction log, and so all the writes come to the server the first one there wins.
You can construct some strange cases where, maybe two people hit enter at the same time, and it's not perfect in the way that a CRDT is. But those are very rare. The simplification that you get from not having to build all that is well worth it.
(This dovetails nicely with a talk I gave a few months ago about how authoritative servers allow you to sidestep a lot of the complexity of CRDTs)
I was also interested in what drove their choice to use Rust:
Paul: Was Rust on the backend a performance-driven concern, or did you just like working with Rust?
Breck: It was a performance and correctness thing.
It was also a bit of a familiarity thing. The team wrote the S3 file system, and that was kind of the first big mission critical Rust project at Amazon. So the team had a bunch of Rust expertise. We knew it well, but one of the things we learned doing the S3 file system was that rust can be very performant.
The real reason we chose it for S3, was not just the speed of the implementation, but the fact that it doesn't do mark-and-sweep GC. And even though that's gotten significantly better in the newer versions of Java, there's still this tail that you have to worry about in any traditionally garbage-collected language.
The Rust tail is much, much tighter.
And then the second thing is Rust just interops really well with these system libraries. Under the hood, when you create an object -- there's so much overhead to doing that in Java. I think the size of an integer in Java is something like 28 bytes, even though you should only need 8 bytes to actually store the thing. That overhead adds up a ton.
Rust gives you this really nice, kind of ergonomic language that feels like you're writing in a higher level language like ML or Haskell, but with the performance characteristics of a C or a C++.
The complete conversation is published as a podcast. Search for "browsertech" in your podcast player.
You can try out Row Zero without signing up (I love when apps let you do that).
For more on this sort of architecture, read my post on session backends and our open-source work on Plane, which implements a similar architecture using containers rather than VMs.
Until next time,
Paul
You just read issue #33 of Browsertech Digest. You can also browse the full archives of this newsletter.